
Most people begin their machine learning journey inside Jupyter notebooks.
I did too.
Notebooks are excellent for experimentation, rapid iteration, and learning new concepts.
But the moment a model needs to operate in the real world, notebooks quickly become a liability.
This realization marked a shift in how I approach AI and ML engineering.
The Problem with Notebooks
Jupyter notebooks are optimized for exploration, not production execution.
As soon as a notebook-based solution is pushed toward deployment, several issues surface:
- Hidden state makes results difficult to reproduce
- Execution order can silently change outcomes
- Data processing, experimentation, and logic become tightly coupled
- Versioning and automated testing are hard to enforce
- Deployment workflows become fragile and error-prone
A notebook can demonstrate that a model works once —
but it cannot guarantee that the model will work reliably over time.
The Shift to Systems Thinking
In production environments, models do not exist in isolation.
They operate as part of larger systems that must handle real data, real users, and real constraints.
Building systems that processed data for 5,000+ stocks forced me to think beyond accuracy metrics.
What mattered most in production was:
- Reproducibility over marginal accuracy gains
- Latency as a first-class requirement
- Monitoring as a core system component, not an add-on
- Understanding that most failures originate from data issues, not model architecture
A model that performs well once is interesting.
A system that performs reliably every day is valuable.
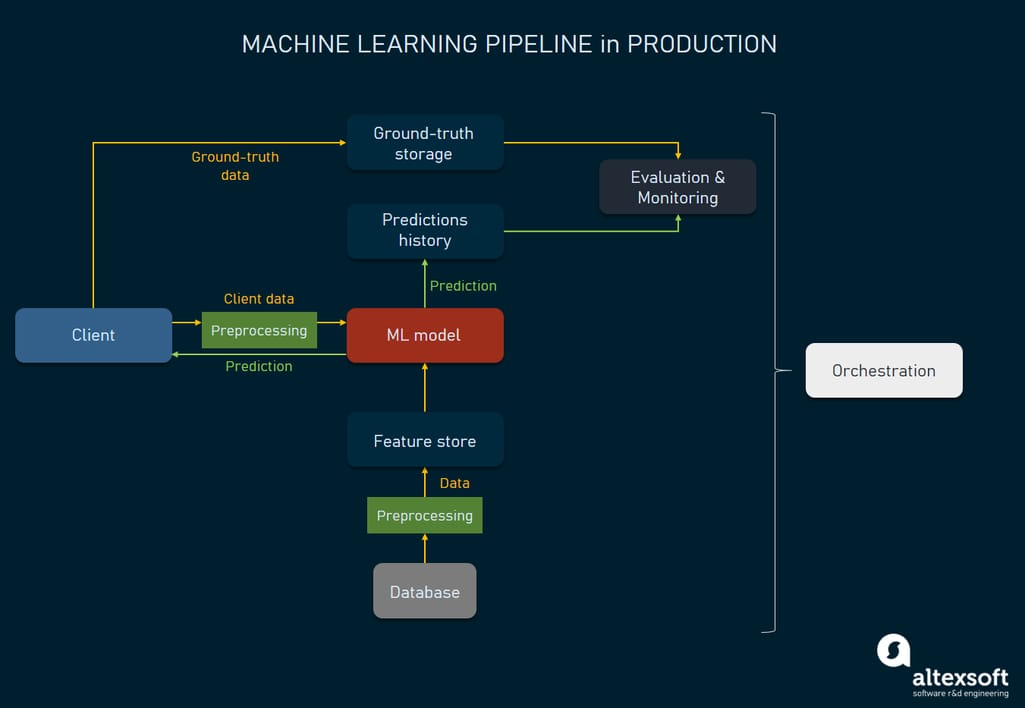
What a Production ML System Looks Like
Production ML is not about a single model file.
It is about designing pipelines with clear boundaries and responsibilities:
- Data ingestion and validation
- Feature preprocessing
- Model inference
- API exposure
- Monitoring and logging
- Deployment and rollback strategies
This structure transforms machine learning from experimentation into infrastructure.
The Stack That Works
For most applied ML systems, simplicity and clarity outperform complexity.
A minimal, production-friendly stack keeps responsibilities explicit and failures easier to diagnose:
# FastAPI + PyTorch + Docker = Production ML
from fastapi import FastAPI
import torch
app = FastAPI()
@app.post("/predict")
async def predict(data: dict):
# Validate and preprocess input
# Run model inference
# Return structured output
return {"prediction": result}
This approach enables:
- Predictable latency
- Easier scaling and monitoring
- Cleaner separation between research and production
Closing Thoughts
Models are important.
But systems are what make models useful.
I still use notebooks for research and exploration.
When it’s time to ship, everything moves into structured, testable, production-grade systems.
Building reliable ML systems requires thinking beyond models — and embracing engineering discipline.