When I scaled our stock prediction system from 48 to 5000 instruments, I thought the hard part was making it run without crashing. Turns out, the real challenge was keeping it accurate over time.
Models don't just "work forever." They drift. And when they drift in production, users notice: bad predictions, lost trust, and angry emails.
This post is about model drift: what it is, why it happens, and how to catch it before it breaks your system. I'll share the techniques I use in production, with code examples you can actually run.
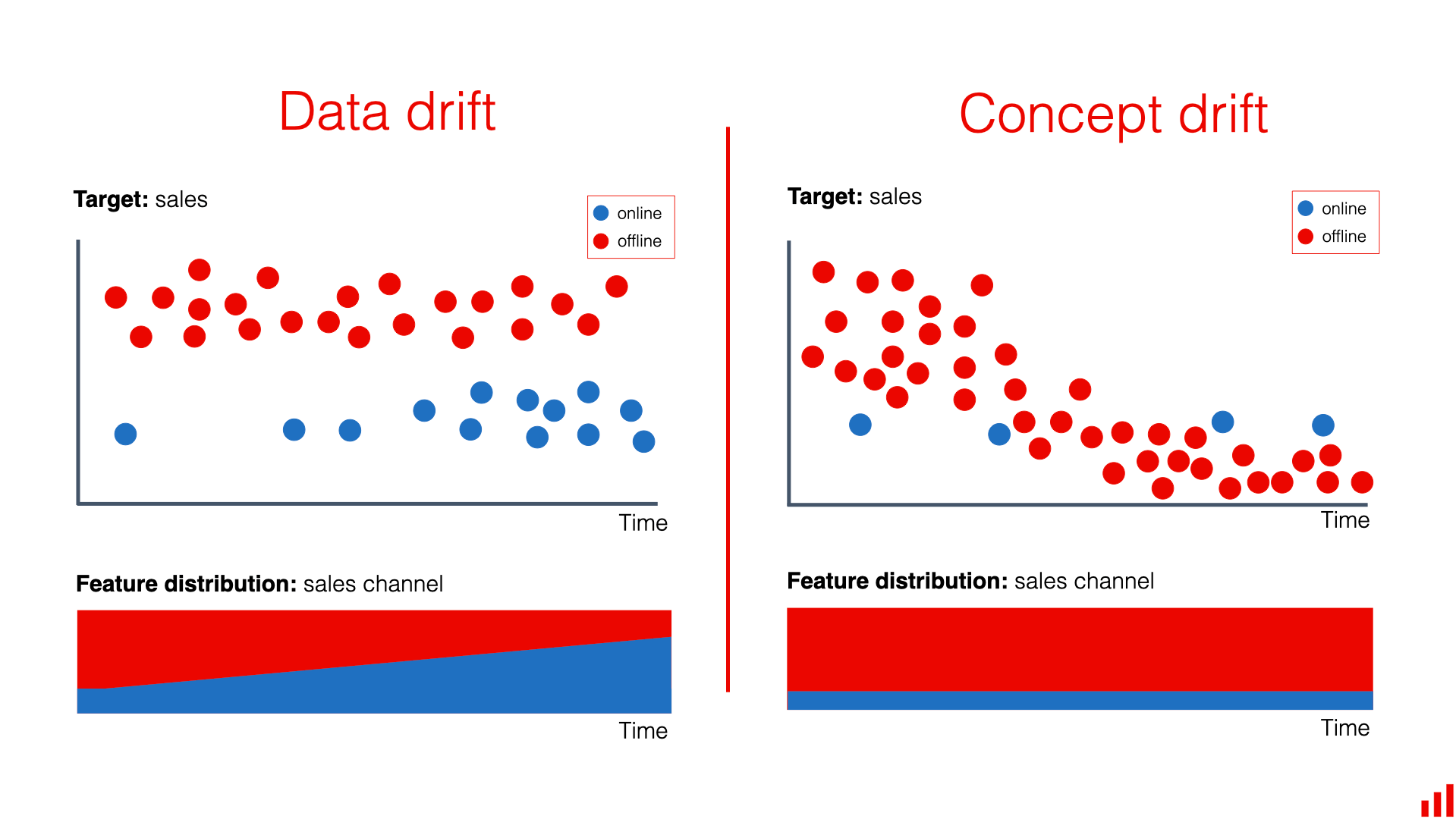
What is Model Drift?
Model drift happens when your model's performance degrades because the real-world data it encounters differs from the data it was trained on.
There are two main types:
1. Concept Drift
The relationship between inputs and outputs changes. For example:
- A stock prediction model trained on pre-pandemic data might not account for COVID-era volatility patterns.
- A recommendation system trained on 2020 user behavior might miss shifts caused by social media trends.
2. Data Drift
The input data distribution changes, but the underlying concept stays the same. For example:
- Sensor readings from IoT devices drift due to hardware aging.
- Customer demographics shift over time.
In my stock prediction system, we see both:
- Data drift: Market volatility spikes during earnings seasons.
- Concept drift: Economic events like interest rate changes fundamentally alter trading patterns.
Why Drift Matters in Production
Drift isn't just an academic problem. It has real business impact.
When our model drifted after scaling to 5000 stocks:
- Prediction accuracy dropped from 78% to 62% in two weeks.
- Users started questioning the platform's value.
- We wasted engineering time debugging "model bugs" that were actually drift.
The scary part? Drift happens silently. Your model keeps making predictions, but they are getting worse. Without monitoring, you will not know until it is too late.
Detecting Model Drift
Detection is about comparing your model's predictions against reality. Here are the practical methods I use:
Statistical Tests for Drift Detection
The Kolmogorov-Smirnov test compares distributions between reference and current data:
from scipy.stats import ks_2samp
import numpy as np
def detect_drift(reference_data, current_data, threshold=0.05):
"""
Detect drift using KS test on feature distributions.
Args:
reference_data: Training/validation data (numpy array)
current_data: Recent production data (numpy array)
threshold: P-value threshold for drift detection
Returns:
bool: True if drift detected
"""
# Test each feature
for feature_idx in range(reference_data.shape[1]):
ref_feature = reference_data[:, feature_idx]
curr_feature = current_data[:, feature_idx]
statistic, p_value = ks_2samp(ref_feature, curr_feature)
if p_value < threshold:
print(f"Drift detected in feature {feature_idx}: p={p_value:.4f}")
return True
return False
# Usage in production
reference_features = load_training_features() # From model training
current_features = get_recent_production_data() # Last 7 days
if detect_drift(reference_features, current_features):
alert_engineers("Model drift detected!")
This catches data drift by comparing feature distributions.
Performance Monitoring
Track key metrics over time:
import pandas as pd
from sklearn.metrics import mean_absolute_error
def monitor_model_performance(predictions, actuals, window_days=7):
"""
Monitor prediction accuracy over rolling windows.
Args:
predictions: Model predictions (DataFrame with timestamps)
actuals: Ground truth values (DataFrame with timestamps)
window_days: Rolling window size in days
"""
# Merge predictions with actuals
df = predictions.merge(actuals, on=["stock_id", "timestamp"], suffixes=("_pred", "_actual"))
# Calculate rolling MAE
df["mae"] = np.abs(df["price_pred"] - df["price_actual"])
df["rolling_mae"] = df.groupby("stock_id")["mae"].rolling(window=window_days).mean()
# Alert if MAE exceeds threshold
current_mae = df["rolling_mae"].iloc[-1]
baseline_mae = get_baseline_performance() # From validation
if current_mae > baseline_mae * 1.5: # 50% degradation
alert_team(f"Performance degradation: MAE {current_mae:.2f} vs baseline {baseline_mae:.2f}")
return df
For our stock system, we monitor:
- Mean Absolute Error on predictions
- Prediction confidence intervals
- Feature importance stability
Population Stability Index (PSI)
PSI measures how much a feature's distribution has shifted:
def calculate_psi(expected, actual, bins=10):
"""
Calculate Population Stability Index.
Args:
expected: Reference distribution
actual: Current distribution
bins: Number of bins for histogram
Returns:
float: PSI value (>0.25 indicates significant drift)
"""
# Create bins
breakpoints = np.linspace(min(expected.min(), actual.min()),
max(expected.max(), actual.max()), bins + 1)
# Calculate percentages
expected_percents = np.histogram(expected, bins=breakpoints)[0] / len(expected)
actual_percents = np.histogram(actual, bins=breakpoints)[0] / len(actual)
# Avoid division by zero
expected_percents = np.where(expected_percents == 0, 0.0001, expected_percents)
actual_percents = np.where(actual_percents == 0, 0.0001, actual_percents)
# Calculate PSI
psi = np.sum((actual_percents - expected_percents) * np.log(actual_percents / expected_percents))
return psi
# Example usage
reference_prices = load_historical_prices()
current_prices = get_current_market_data()
psi_score = calculate_psi(reference_prices, current_prices)
if psi_score > 0.25:
print(f"Significant drift detected: PSI = {psi_score:.3f}")
PSI greater than 0.25 means significant drift. We use this for our market data features.
Implementing Drift Detection in Production
Here is how we integrated drift detection into our ML pipeline:
# drift_monitor.py
import asyncio
from datetime import datetime, timedelta
import logging
class DriftMonitor:
def __init__(self, model, reference_data, alert_threshold=0.05):
self.model = model
self.reference_data = reference_data
self.alert_threshold = alert_threshold
self.logger = logging.getLogger(__name__)
async def check_drift(self):
"""Periodic drift check"""
while True:
try:
# Get recent production data
current_data = await self._fetch_recent_data()
# Run drift detection
drift_detected = self._detect_drift(current_data)
if drift_detected:
await self._handle_drift(current_data)
# Check every 6 hours
await asyncio.sleep(6 * 3600)
except Exception as e:
self.logger.error(f"Drift monitoring failed: {e}")
def _detect_drift(self, current_data):
"""Run multiple drift detection methods"""
# Statistical test
stat_drift = detect_drift(self.reference_data, current_data)
# PSI check
psi_scores = []
for feature_idx in range(current_data.shape[1]):
psi = calculate_psi(
self.reference_data[:, feature_idx],
current_data[:, feature_idx]
)
psi_scores.append(psi)
avg_psi = np.mean(psi_scores)
psi_drift = avg_psi > 0.25
return stat_drift or psi_drift
async def _handle_drift(self, current_data):
"""Handle detected drift"""
self.logger.warning("Model drift detected!")
# Log drift details
await self._log_drift_details(current_data)
# Trigger retraining if severe
if self._is_severe_drift(current_data):
await self._trigger_retraining()
# Alert team
await self._send_alert()
async def _fetch_recent_data(self):
"""Fetch recent production data"""
# Implementation depends on your data storage
# Could be from Redis, database, or API
pass
def _is_severe_drift(self, current_data):
"""Determine if drift requires immediate action"""
# Check performance degradation
performance_drop = self._calculate_performance_drop(current_data)
return performance_drop > 0.3 # 30% drop
async def _trigger_retraining(self):
"""Trigger model retraining pipeline"""
# Could send message to queue, call API, etc.
pass
# Start monitoring
monitor = DriftMonitor(model, reference_data)
asyncio.create_task(monitor.check_drift())
This runs continuously, checking for drift every 6 hours and alerting when needed.
Handling Drift When It Happens
Detection is only half the battle. You need a response plan:
1. Alert and Investigate
- Notify the team immediately
- Log detailed drift information
- Analyze what changed (new data patterns, external events)
2. Short-term Mitigation
- Fallback to simpler models
- Increase prediction uncertainty bounds
- Manual overrides for critical predictions
3. Long-term Solutions
- Retrain the model with recent data
- Update feature engineering
- Implement continuous learning pipelines
For our stock system, when drift hits:
- We alert via Slack
- Switch to a conservative prediction strategy
- Queue a retraining job that runs overnight
Tools and Libraries
Here are the tools I recommend:
- Alibi Detect: Comprehensive drift detection library
- Evidently AI: ML monitoring and drift detection
- Apache Kafka + Flink: Real-time drift detection pipelines
- Prometheus + Grafana: Metrics monitoring and alerting
For our system, we use a mix of custom code and Alibi Detect for complex drift scenarios.
Lessons from Production
After a year of monitoring drift:
- Drift is inevitable - Plan for it from day one
- False positives are okay - Better to check than miss real drift
- Data quality matters more than algorithms - Most "drift" is actually data issues
- Monitor everything - Features, predictions, and system health
- Automate responses - Manual intervention should be the exception
Closing Thoughts
Model drift turned our "working" ML system into a reliable one. Without drift detection, we would still be chasing phantom bugs.
The key insight? ML in production is not about building perfect models - it is about building systems that adapt.
If you are deploying ML models, start monitoring drift today. Your future self will thank you.
Questions about drift detection or production ML? Reach out at [email protected] or connect on LinkedIn at linkedin.com/in/alipatel786